Introduction
It has been a long time since my blog post (because of Covid, work, Elden Ring...). So I decided to study the "Spectral Primary Decomposition for rendering with sRGB Reflectance", which used in previous posts, to recall my memory. It is an efficient technique to up-sample sRGB texture to spectral reflectance by multiplying the sRGB values with 3 precomputed basis functions:
 |
| Overview of "Spectral Primary Decomposition" from the Explanatory Poster |
Porting to Octave
In the paper, it provides sample source code written in Matlab. Since I do not have a Matlab license, so the first thing I need to do is to port the source code to the open source Octave (ported source code can be found here). During the porting process, the fmincon() used for finding the 3 spectral primary basis functions in Octave does not work, so I switched to use sqp() instead (also removed the linprog() from original source code).
 |
| Basis Functions generated in Octave |
The resulting graph is not as smooth as the original paper. So I decided to try different initial value for the objective function. I chose a normalized Color Matching Function:
|
|


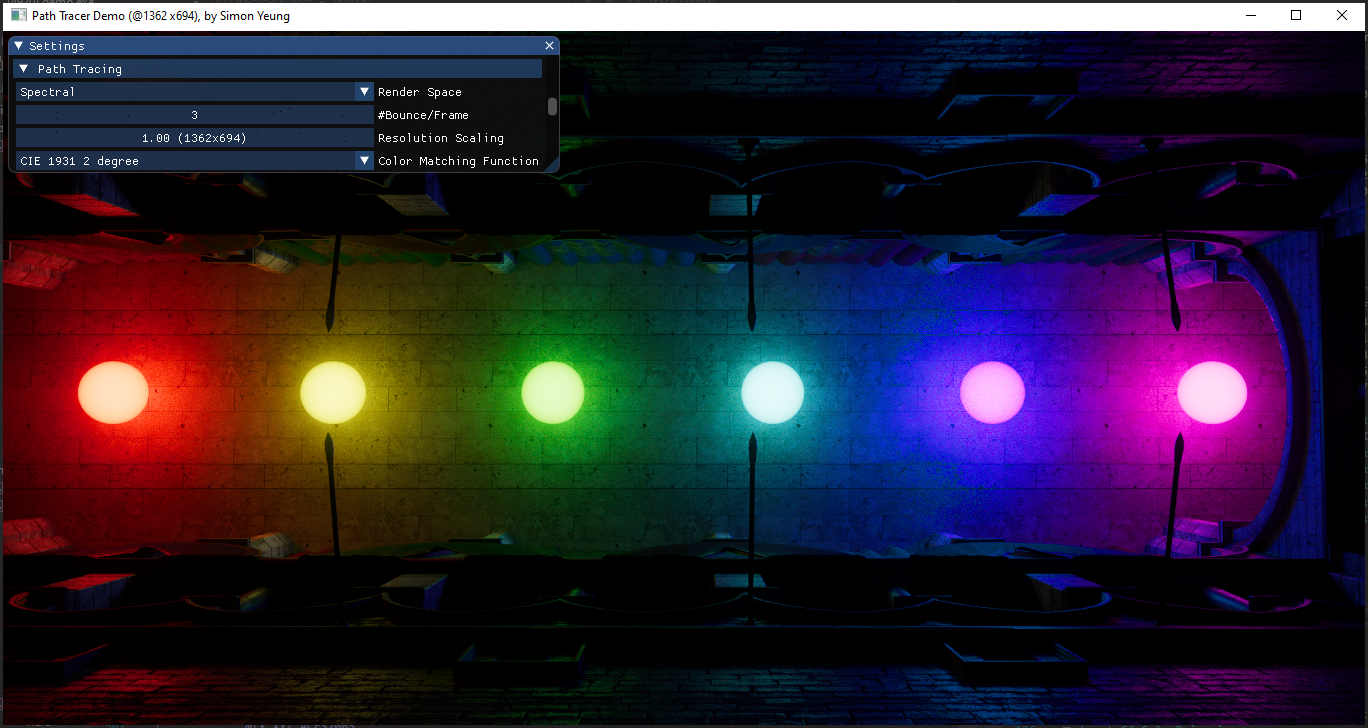
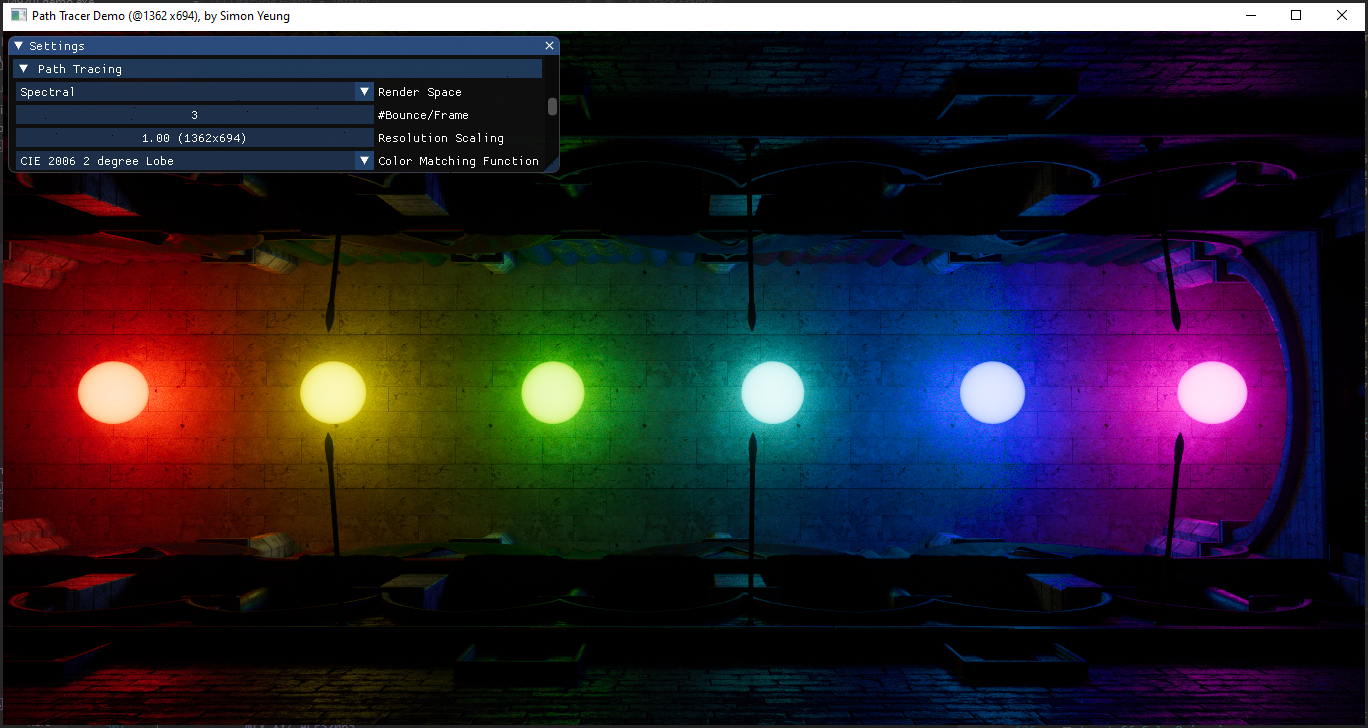
The resulting curves look smoother with normalized CMF as initial value. Also, during the porting process, I switched to use CMF2006 2 degree observer instead of CMF1931 / 2006 10 degree observer used in original source code.
Working with wider gamut
So the next step is to change the color primaries from sRGB to Display-P3 (which the original source listed as infeasible). As expected, the result is not good, not only saturated color cannot be up-sampled, the color within the sRGB gamut are not similar to the original color, and saturated red color will have an orange tint after up-sampling: (Note that below images have Display-P3 color profile attached, to view those saturated color outside sRGB gamut, a wide gamut monitor is needed)
|
|
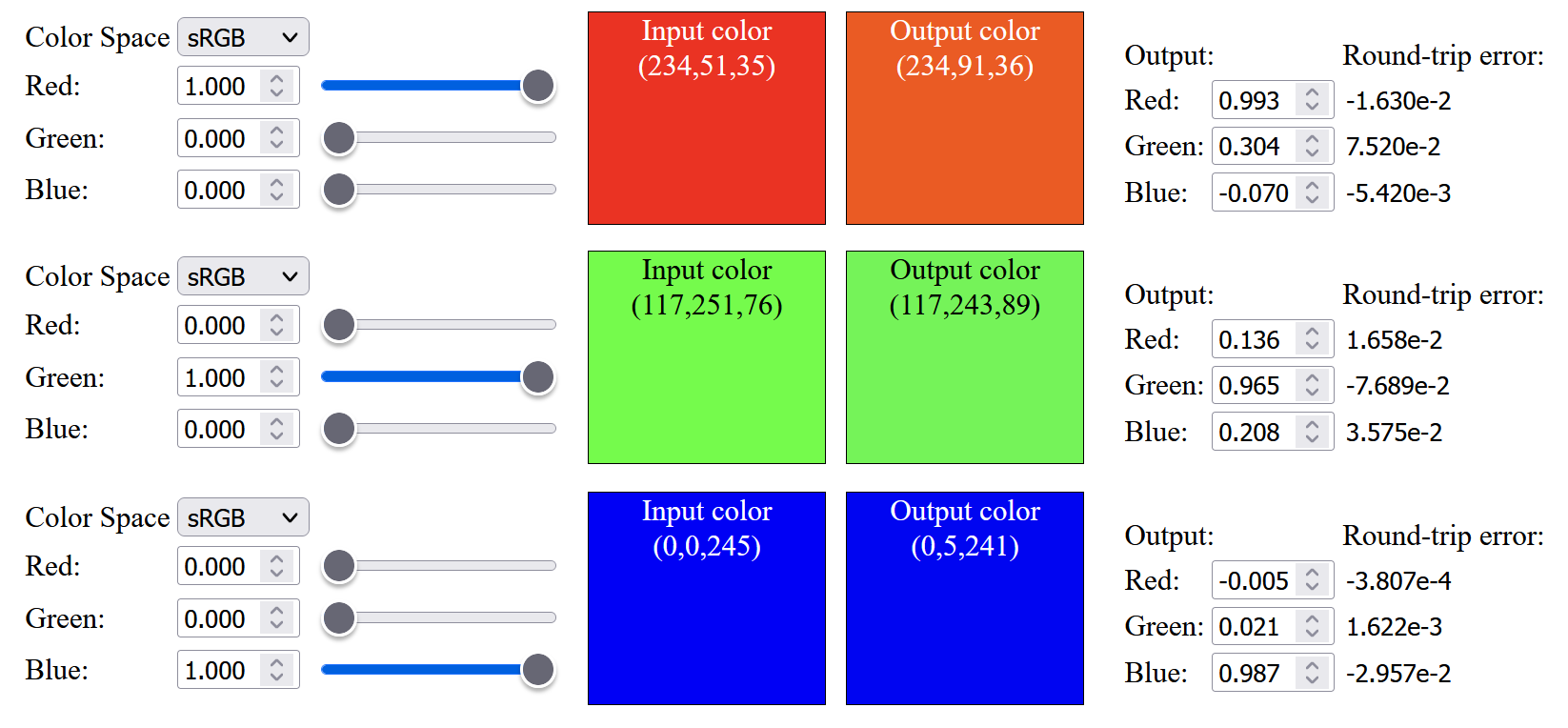
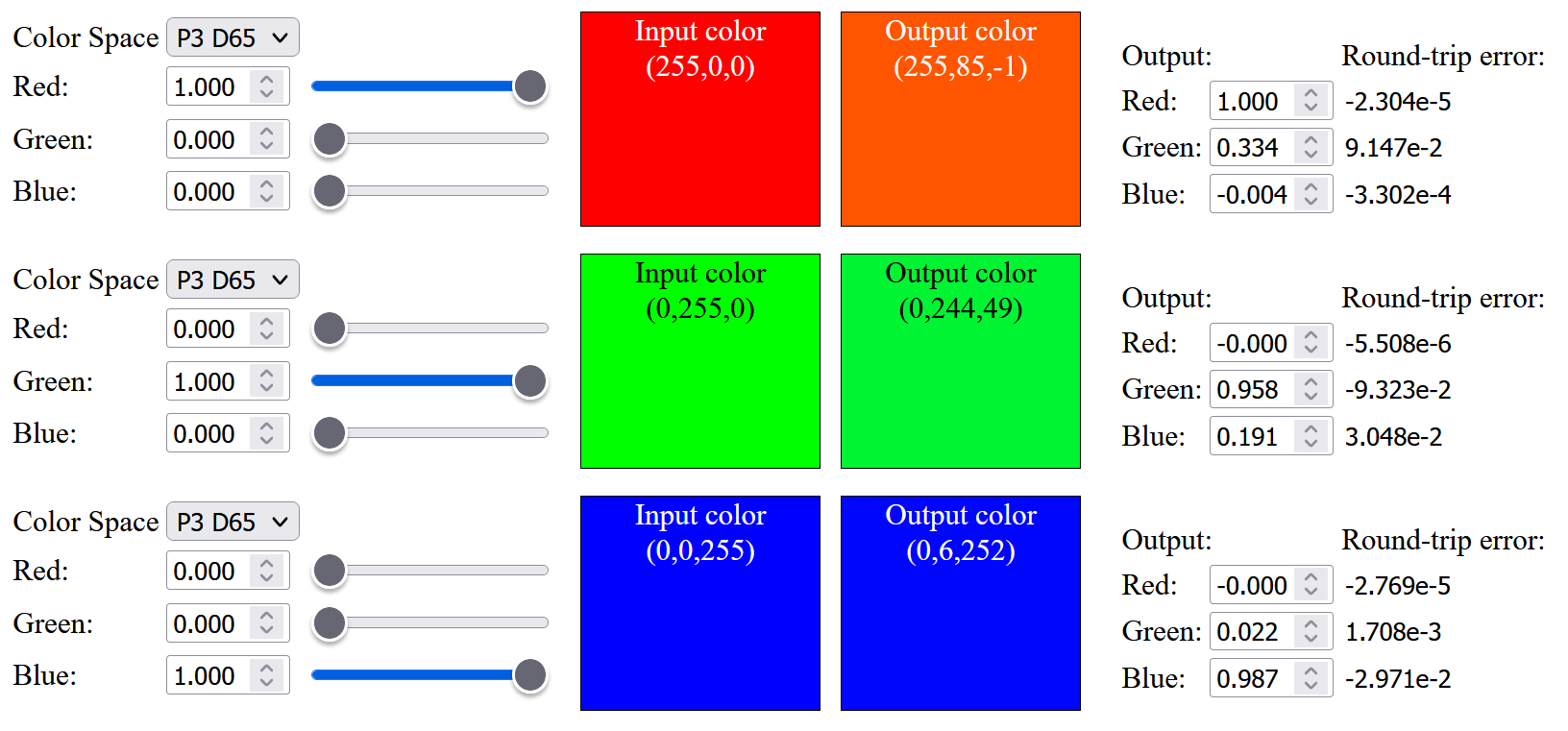
So, I tried to modify the objective function opt_fn() used in sqp() to include a weight to minimize the sRGB primaries color difference:
 |
| Code snippet of the objective function with sRGB primaries weight |
The result improves a bit and the up-sampled saturated red has a less orange tint:
|
|

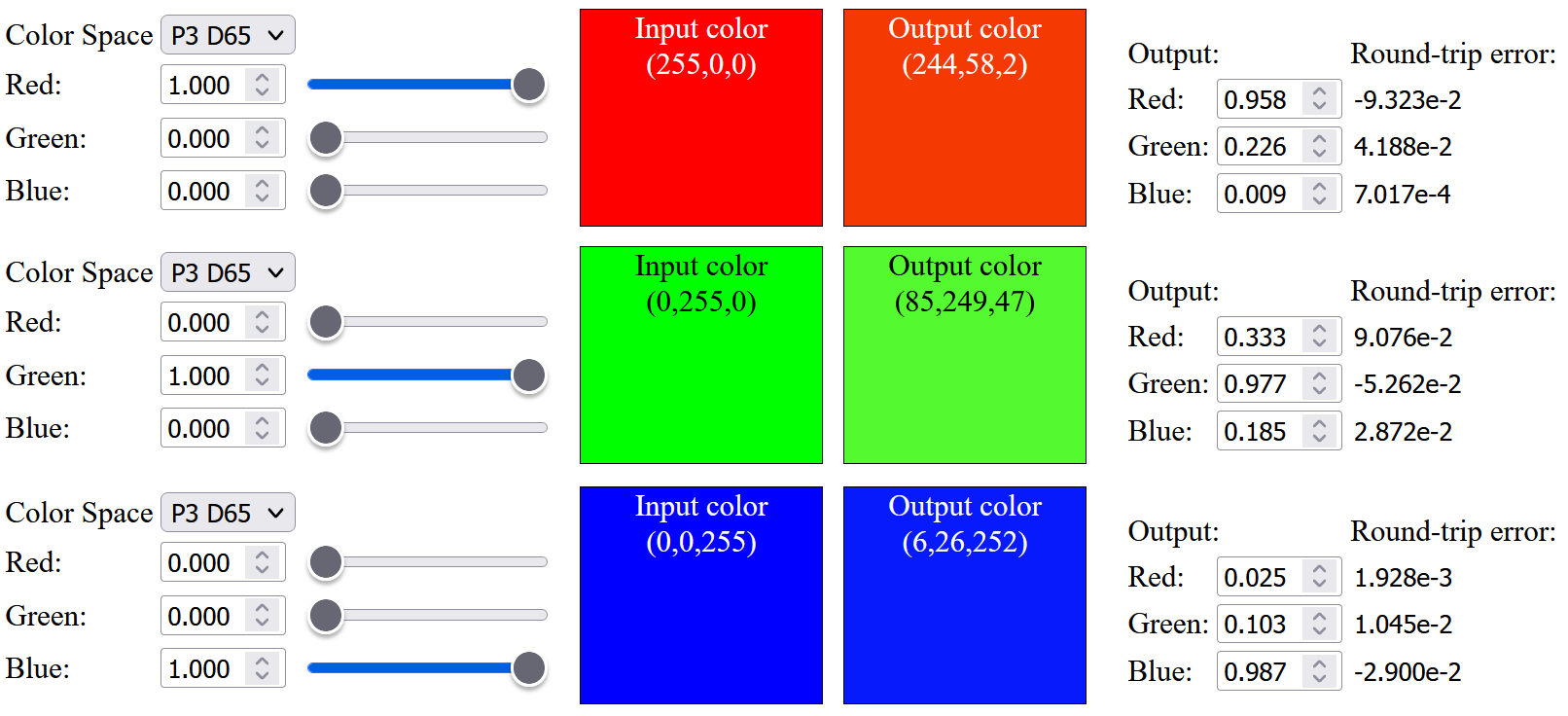
Up to this point, all the precomputed spectral primary basis functions are within [0, 1] range (i.e. to not reflect more light in each basis function), I was wondering what if we relax this constraint and enforce this limit after linearly combining all the basis functions. I have tried to relax the range of individual basis function to [-0.05, 1.05], [-0.075, 1.075] and [-0.1, 1.1] (details can be found in the visualization website from modified source code). With the relaxed range, we can get very similar sRGB color after up-sampling:

The up-sampled saturated red is having a visible difference from the original color before up-sampling, I have tried to modify the objective function to only optimize the Red basis function (ignoring the Green and Blue basis functions), and still cannot get an exact up-sampled saturated red from a D65 light source. May be it is impossible to produce the most saturated Display-P3 red with a D65 light source without violating the physical constraint.
Out of curiosity, I tried to plot the chromaticity diagram of the up-sampled color. The result shows that, using limited [0, 1] range, the up-sampling process can produce "more color" (but not accurate, e.g. red color will be up-sampled to "orange-red"), while using relaxed constraint will reduce the up-sampled color gamut.
|
|


CMF Reference White
Up to this point, the calculation for the up-sampled color is using D65 as reference white. But one day, I saw this tweet:

The CMF is using an equal-energy white as its reference white. So I was wondering whether all my calculation was wrong and should add chromatic adaptation after CMF integration.
So, I decided to find the spectral reflectance of color checker to integrate with the CMF to verify whether chromatic adaption are needed after CMF integration. Using the color checker data found from here, illuminating those grey patches with D65 and then integrate the result with CMF get the following results:
|
|


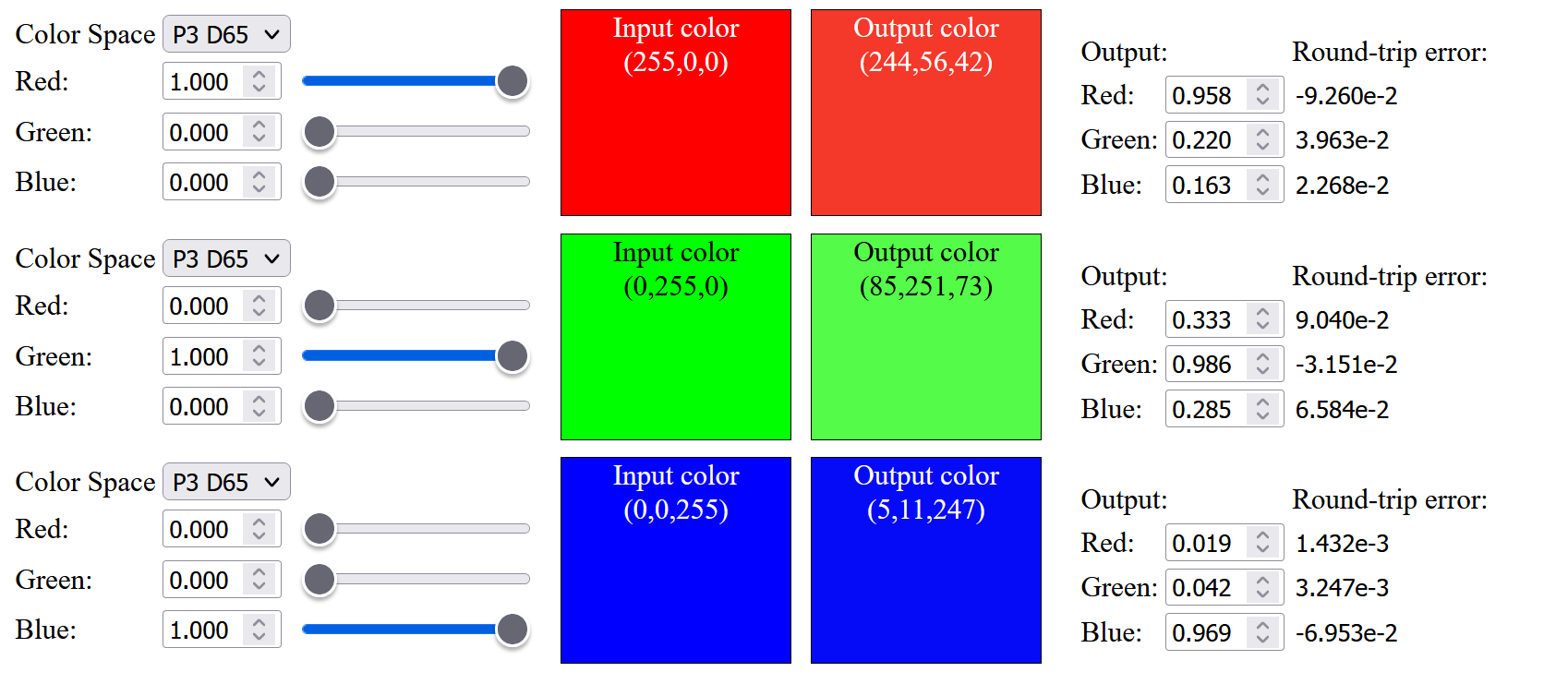
Our computed sRGB value are very similar to the measured data, so it seems like we don't need an extra chromatic adaption to adapt the color from the CMF equal-energy reference white (or please let me know if my maths are incorrect).
Optimizing up sampling function with Color Checker Data
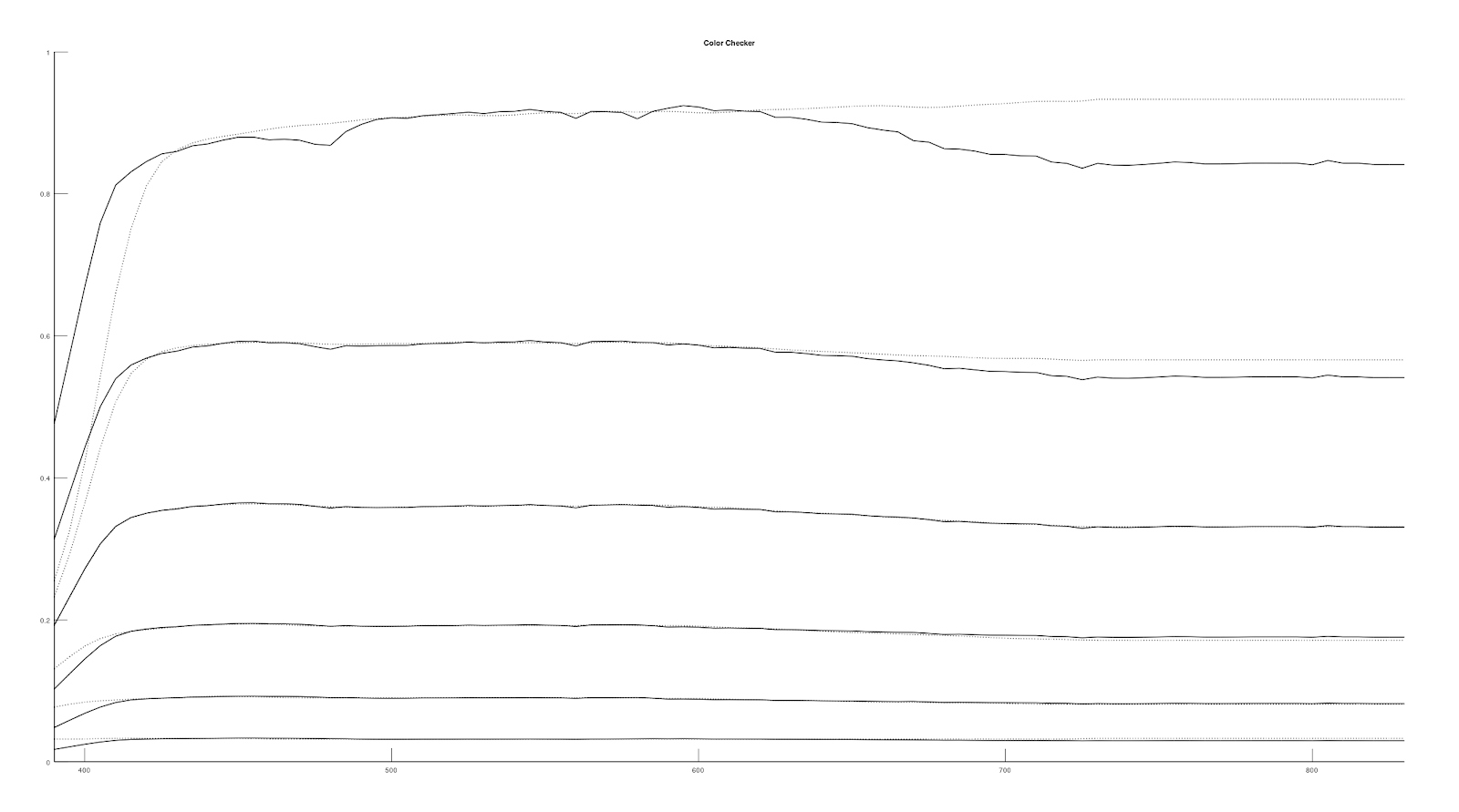
After working with color checker data, I came up with an idea to modify the spectral basis objective function to include a weight to bias it to match with the neutral 6.5 grey patch spectral reflectance data. We can get a decent match for the up-sampled spectral reflectance of color checker grey patches (i.e. white 9.5, neutral 8, neutral 6.5, neutral 5, neutral 3.5, neutral 2).
|
|
||||
|
|



However, the up-sampled white color will have a slight round-trip error:

Conclusion
In this post, I have ported the original "Spectral Primary Decomposition" source code to Octave, tried to change it to up-sample Display-P3 color, but the result is not very good. Also, within a game engine, we usually have exposure and tone mapping adjustment, which affect the final pixel color. So I was wondering whether the up-sampling method should take those parameters into account. But doing so, the texture color meaning will be different from the PBR albedo texture. So, I will leave it for future investigation.
References
[1] https://graphics.geometrian.com/research/spectral-primaries.html
[2] http://yuhaozhu.com/blog/cmf.html
[3] https://babelcolor.com/colorchecker-2.htm